Skip to content
Home
About
Products
Voice and Interaction
Security
Multimodal
On-device documentation assistant
Gate
Panel for Meeting Room
Learn Center
Why Ethos-U55
Technology & Kits
Proofs & Resources
Contacts
Home
About
Products
Voice and Interaction
Security
Multimodal
On-device documentation assistant
Gate
Panel for Meeting Room
Learn Center
Why Ethos-U55
Technology & Kits
Proofs & Resources
Contacts
On-device documentation assistant
based on context-aware passage retrieval
When users need to find, enable, or fix something
Instruction unavailable (lost, outdated, never provided)
Hard to find the needed info inside the documentation
Needed immediately, not after reading manuals
Inconvenient to use (on the move, low light, one hand)
Users want quick and clear answers— not manuals
So how do we make the device explain itself?
Template-based systems
rigid
limited
poor user experience
Cloud-based / generative assistants
require internet and subscriptions
unpredictable behavior
hallucinations are unacceptable
impossible to certify for safety-critical devices
On-device assistant with deterministic behavior
Let’s see how it works
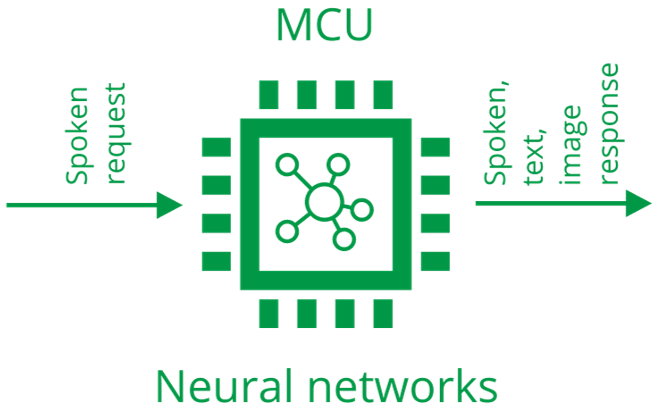
A voice-based question–answering system
Runs entirely on a microcontroller
Uses neural networks, but behaves deterministically
Responses are based only on official device documentation
Clear, deterministic guidance with visual + voice instruction
Safety
Convenience
Hands-free access to official specs
Instant access to vehicle documentation with hands-free interaction
No connectivity dependency
Safer, more confident user experience
Critical guidance in complex systems
Deterministic answers from official manuals
Works in environments with no connectivity
New interactive experience
Safe, bounded knowledge domain
No cloud, no data leakage, safe by design
Deterministic behavior
No hallucinations by design
Retrieval, not generation
Answers come only from the documentation
Same input → same output
Behavior is predictable and testable
Implications:
Trustworthy responses
Suitable for regulated and safety-critical products
Markets
Auto
Consumer
Vehicles
Toys
Benefits
Privacy
User requests never leave the device
Costs
No cloud APIs
No subscriptions
Zero runtime cost after deployment
Certification
Deterministic logic
Easier compliance with safety standards
Technical Overview
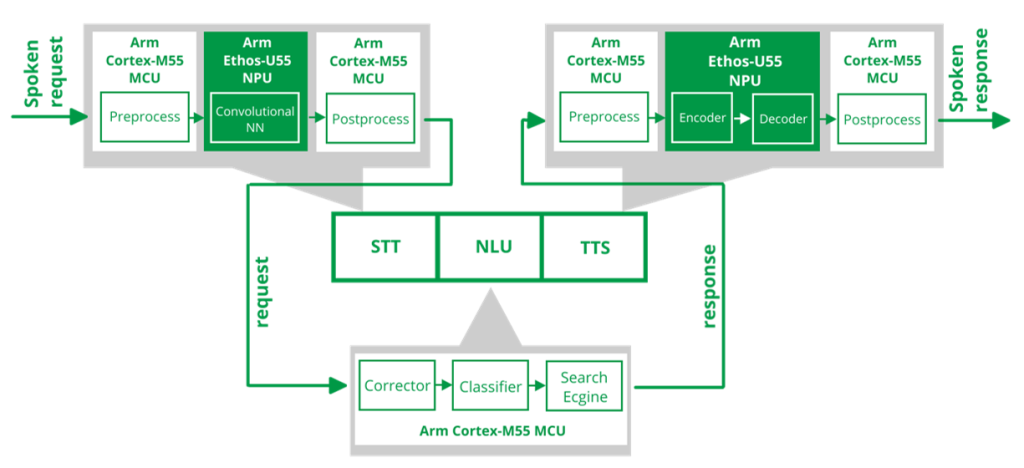
Hardware
Alif Ensemble 7 AI/ML App Kit
Heterogeneous MCU architecture for on-device AI
two
Arm Cortex-M55
One up to 160 MHz
One up to 400 MHz
two
Arm Ethos-U55
One up to 128 MAC/cycle (≈46 GOPS)
One up to 256 MAC/cycle (≈204 GOPS)
400 MHz 64-bit AXI bus common across CPUs
Ethos-U55 + M55 achieves
~800× faster inference performance
compared to Cortex-M alone
System architecture
Real-time factor (rtf): 0.3
rtf =
Processing Time
Audio Length
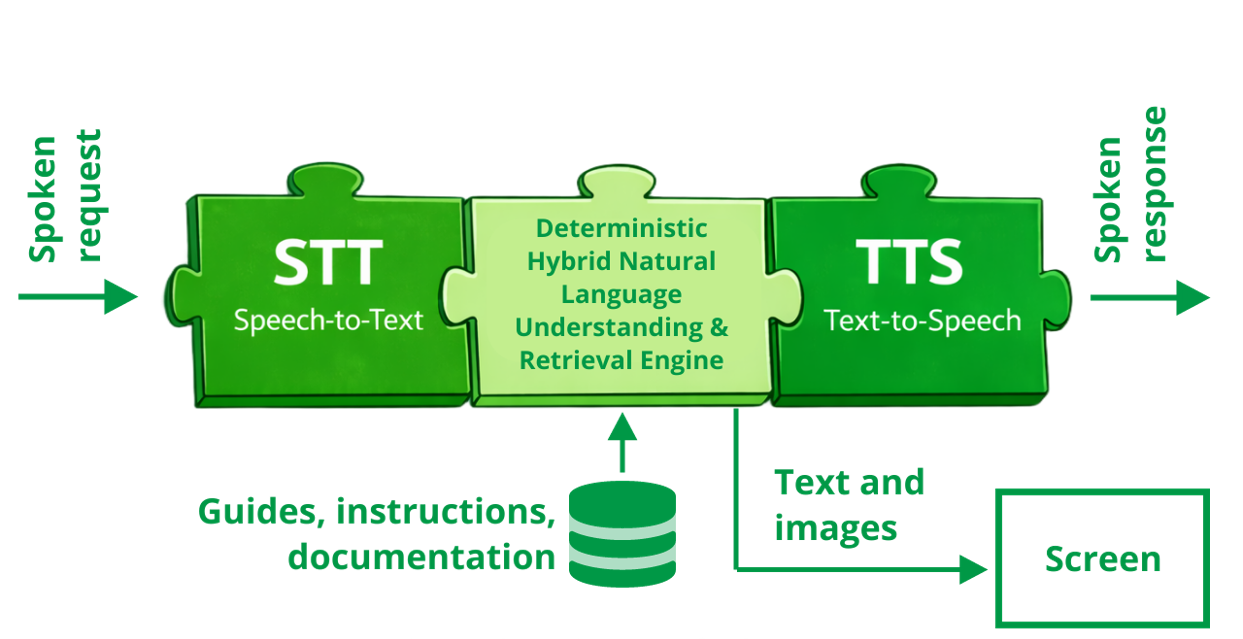
Components
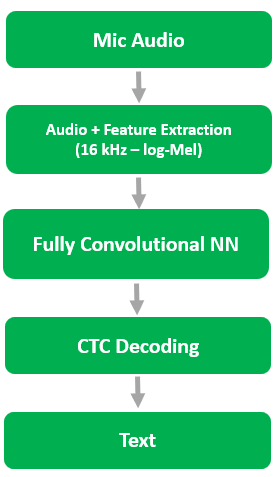
Speech-to-Text (STT) module
Based on convolutional architecture
Fully convolutional model — no RNNs or transformers
Optimized for deterministic, low-latency execution
Processes 16 kHz audio via log-Mel spectrogram features
~19 million parameters
3.9% WER on LibriSpeech test-clean
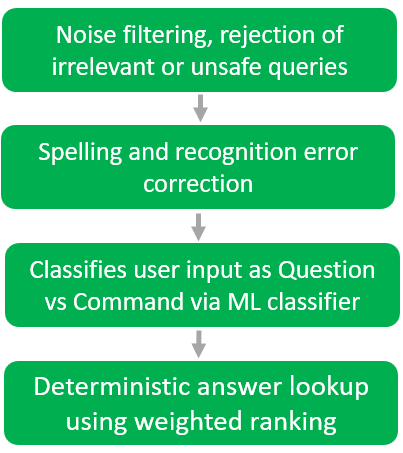
Deterministic Hybrid NLA&Retrieval Engine
What this module does
Interprets user intent and context
Corrects recognition errors before search
Retrieves documented answers
Prepares the response
Text-to-Speech (TTS) module
Text normalization and phonemization
Chunk-based processing for long inputs
Neural acoustic model
GAN-based neural vocoder
Seamless audio stitching
How to start with us
Device makers, startups & design houses
Evaluate the prototype based on the Alif Ensemble 7 AI/ML Appkit
Co-develop a Proof of Concept
Develop the full system
Deploy / License the solution
Microcontroller & silicon vendors
Port & optimize modules for partner MCU/NPU platforms
Create reference designs & demo kits
Co-market & build ecosystem partnerships
Support engineers & customers – demo & sales support
Any questions left?
Name
Email
Message
Send